Як відновити дані зі сховищ NetApp ONTAP
Рішення для зберігання даних NetApp ONTAP є доволі специфічними через свою унікальну архітектуру, у якій поєднується WAFL (Write Anywhere File Layout) із пропрієтарними конфігураціями RAID, оптимізованими для цієї файлової системи. Стандартні інструменти для відновлення даних зазвичай не можуть бути застосовані до цих систем, які вимагають спеціального підходу і просунутого програмного забезпечення, як-от UFS Explorer Technician. Ця утиліта може працювати зі специфічними технологіями NetApp, забезпечуючи належну реконструкцію сховища та відновлення даних з нього за певних сценаріїв. У цій статті описана внутрішня структура систем NetApp ONTAP і пояснюється, як виконати відновлення інформації з цих сховищ за допомогою UFS Explorer Technician.
Підтримка NetApp ONTAP в UFS Explorer
UFS Explorer Technician пропонує обмежену підтримку відновлення даних зі сховищ NetApp під керуванням операційної системи ONTAP і файлової системи WAFL. Йдеться про те, що програмне забезпечення може працювати лише з певними сценаріями та технологіями, реалізованими в WAFL.
Програмне забезпечення підтримує наступні технології:
розміщення даних (layout) формату "на диску" файлової системи WAFL – версії 2, 3 і 4;
як класичні, так і FLEX томи;
RAID-P і RAID-DP (реконструкція за наявності всіх дисків або якщо бракує лише одного з них);
стиснення та дедуплікація даних (експериментальна підтримка).
Технології, які НЕ підтримуються:
WAFL версії 1 і будь-який тип розміщення даних (layout), новіший за версію 4;
RAID-DP, у якому відсутні два диски.
Хоча WAFL можна просканувати у пошуку видалених томів і файлів, ця функція наразі не реалізована. Це означає, що сценарії відновлення даних, з якими може впоратися програмне забезпечення, обмежуються наступними випадками:
збої RAID;
збої ОС/контролера;
втрата доступу до системи.
Опис системи
Сховище NetApp Data ONTAP складається з одного або кількох дискових відсіків, заповнених дисками SAS або SATA/FATA. У більшості сучасних систем використовуються диски SAS, відформатовані з секторами розміром 520 байт.
Диски групуються в набори RAID, які називаються "агрегатами" ("aggregates"). Найпоширенішою конфігурацією є RAID-DP (Dual-Parity чи подвійна парність). Кожен агрегат містить один "класичний" том WAFL (який зазвичай не використовується) і один або більше томів FLEX, кожен з яких представляє "ізольовану" файлову систему. Ці томи FLEX спільно використовують дисковий простір агрегату.
Розміщення даних на диску
Найчастіше дані зберігаються на дисках SAS із розміром сектора 520 байт. На відміну від більшості подібних систем, де 512 байт містять дані, а 8 байт містять метадані, NetApp використовує кластери 8 секторів: 520 байт перших 7 секторів і 456 байт останнього сектора.
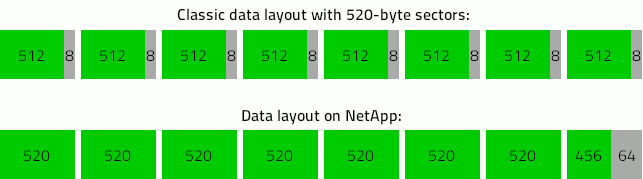
Тож для коректного перетворення даних потрібен особливий підхід (див. нижче).
Потім диски групуються в набори RAID із виділеними компонентами парності:
Кожен диск містить метадані на початку та в кінці, які визначають його положення у наборі RAID. На відміну від традиційного RAID, у цьому випадку ротація даних на рівні RAID відсутня: натомість ротацією між дисками керує WAFL.
Реконструкція тому в UFS Explorer
Необхідно створити повні прості (пласкі чи plain (flat)) образи дисків, що міститимуть кожен байт даних, що зберігається на накопичувачах. Іншими словами, якщо система використовує диски SAS із 520-байтними секторами, усі 520 байт із кожного сектора мають бути збережені в образі.
Після цього потрібно відкрити всі наявні образи дисків в UFS Explorer Technician. Якщо вихідні диски (з яких були створені образи) належать до типу SAS із секторами розміром 520 байт, слід застосувати перетворення розміру сектора (з 4160 у 4096 байт). Таким чином, 64 байти метаданих у кожному 8-му секторі будуть пропускатися.
Після застосування перетворення програмне забезпечення повинно мати змогу виявити (за допомогою суперблоку) правильне зміщення даних (offset) і розмір області даних на диску.
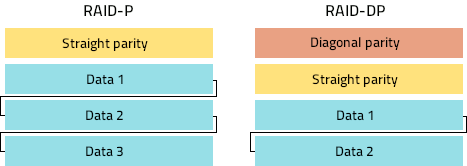
У випадку RAID-P перший диск містить парність, а всі інші диски містять дані у формі SPAN. Отже, треба створити складений (spanned) том, використовуючи розділи даних кожного диска з даними, розташувавши їх у правильному порядку та пропустивши диск з парністю.
У випадку RAID-DP розміщення даних здебільшого те саме. Перший диск містить діагональну парність, другий – пряму парність, а потім за ними йдуть диски "даних". Це означає, що два перші диски ("парності") потрібно пропустити.
Якщо один з дисків RAID-P або DP відсутній, можна відтворити масив за допомогою "Калькулятора парності": використовувати дані з наявних дисків, а також інформацію "прямої" парності (перші диски з RAID-P чи другий з RAID-DP).
Після того, як spanned-том буде зібраний, програмне забезпечення матиме змогу автоматично розпізнати файлову систему WAFL.
Останнє оновлення: 20 лютого 2025